Catherine West gave an excellent closing keynote to Rust Conf on
using Rust for game development which delved into using an ECS at the core of a
game engine and in particular focusing on Data Driven architecture over a more
traditional OOP approach.
What is an Entity-Component System (ECS)
ECS is an inversion of the OOP principals. Rather than workig from a
subject-verb perspective, that is “The Dog acts,” we invert the language to make
the verb promenent: “The Dog is acted upon.”
We do this by removing all data and methods from the “Dog” entity, and focus our
design around verbs: input, animate, render, etc. The verbs are components, the
thing acted upon is an entity which is a type.
This is a kind of Data Driven Programing where the data defines the
implementation details of the business logic rather than the code defining the
available business methods.
What is the Benefit of an ECS
An ECS removes the need to hard-code business relationships between entities
such that rapid prototyping of business logic becomes possible.
This results in:
- Building systems where stakeholders can modify business rules on the fly
- Building concepts that cross-cut through many objects
- Increased agility
- Can take advantage of parallel processing
- Becomes a replacement of the observer pattern
Cowboy Programming in Evolve your Heirarchy describes some of the
disadvantages of moving forward without an ECS. Namely, a deep heirarchy that is
difficult to manage, and the creation of god-objects to resolve common code
duplication.
Notes on Implementation
T-Machine posits in Entity Systems are the Future that an ECS
is not a programming paradigm but a type of system that exists in a larger OOP
application that solves issues that OOP handles poorly. In practice it becomes
an encoding of our business relationships into either a in-memory RDBMS or atual
RDBMS (depending upon thuroughput needs).
A component, according to T-Machine, is an aspect of an entity. It contains a
bucket of properties that define the entity from that aspect.
A system, according to T-Machine, contains all the actions that can be performed
to mutate a component. A system performs it’s actionas against all entities with
a particular aspect.
Example: We have dog-1, dog-2, dog-3. Each is an entity (in production usage
these would be GUIDs). Each of these entities is entered into the component
table as having the moveable component which pivots to a table defining the
position and velocity. The move system runs, applies velocity to each
component’s position and then updates the position properties.
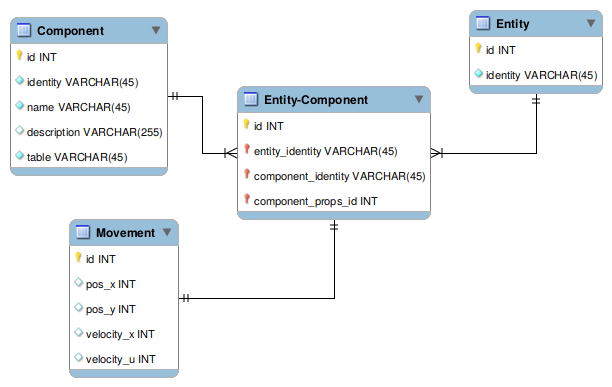
In practice our table structure looks like:
Component table:
| id |
identity |
name |
description |
table |
| 1 |
1234-abcd-efgh |
renderable |
Render entity |
render |
| 2 |
5678-efgh-lmno |
movable |
Update pos. |
movement |
| 3 |
9012-lmno-pqrs |
destructable |
Manage health |
destruct |
Entity table:
| id |
identity |
| 1 |
1234-abcd-efgh |
| 2 |
5678-efgh-lmno |
| 3 |
9012-lmno-pqrs |
Entity-Component pivot:
| id |
entity_identity |
component_identity |
component_props_id |
| 1 |
1234-abcd-efgh |
1234-abcd-efgh |
1 |
| 2 |
5678-efgh-lmno |
1234-abcd-efgh |
2 |
| 3 |
1234-qbcd-efgh |
5678-efgh-lmno |
2 |
Finally the component data table (“movement”)
| id |
pos_x |
pos_y |
velocity_x |
velocity_y |
| 1 |
10 |
20 |
0.5 |
0 |
| 2 |
30 |
40 |
0 |
1 |
As an explanation of the above, we have three entities and three components. The
first entity is renderable and movable, the second entity is movable (but not
renderable). Looking into the movement table we see the first entity has an x/y
position and is moving along the x axis. The second entity has an x/y position
and is moving on the y axis.
We can add and remove entities from these tables.
T-Machine also notes that we can have “assemblers” to create various component
quickly by bundling together similar collections of components and naming them.
I do wonder if some factory or abstract factory style pattern fits in there.
")
Sometime last Winter Nelson Elhage’s essays on using lab
notebooks for software engineering made the rounds on Hacker News. One item in
the early essay struck a cord with me:
Computer scientists are taught to document the end results of their work, but
aren’t, in general, taught to take notes as they go
This seems to be current standard protocol for software versioned with git where
care is taken to currate the repository history. Rather then record every wrong
step and dead-end branch we are taught to prune and re-write the record by
squashing our merge histories. A half-dozen commits showing the history of
iterating on a problem are, in an instant transformed into a single commit as
though the solution sprung spontaneously from the prior commit.
The result is that there is little record of the wrong turns that you took or
the iterative steps taken to disover and correct errors from the initial
design. Without a record of what has already been tried, it is easy to
unneccessarily repeat your own footsteps or forget the reason behind a
particular design call.
How I Use It
I may work with a lot of folks with backgrounds in science, but I myself was not
trained in the discipline. Likewise, most of my work is hardly novel or
experimentive – I make bog standard business software. So the metaphor of an
“experiment” can feel stretched at times.
Digging into the question of what is a lab notebook and how does one keep one, I
stumbled upon an excellent document put together by the National
Institutes of Health. I derrived from it a practice that I started last December
and continue to refine.
What is a lab notebook anyway?
The lab notebook is a bound append-only volume that provides a record of design
decisions, procedures, tooling, observation, and background/reasoning for a unit
of development work. In my case, it is a Leuchtturm1917 bound notebook which
already includes an index, numbered pages, and space to record the date of each
entry.
What it is not: a journal, a record of communication, or a place to compile
standard operation procedures.
What does an entry look like?
Each entry is composed in pen (remember it’s append-only!). I begin a new entry
for each user-story, bug report, or task as I begin work on them. The entries
themselves become intersparsed as they represent the flow of my attention
through the work day. I may take up an entry for a user-story, on the next page
start an entry for a bug, then pick up the user-story again on the following
page.
Each entry must include the following:
- The date the work was done
- A reference title (to connect together intersparsed entries)
Each entry may have the following sections:
- The goal which states in one sentence our desired outcome
- A discovery section which states any pre-conceptions and predicates to our
problem.
- A design plan which states, given our discoveries, the solution we believe
will resolve the goal.
- A test plan which states how we will determine that the design plan has
met the goal
- An observation section, which is perhaps the most important section and I
will detail below
- A next steps section to highlight any new tasks that may have spawned
from the completion and observation of the prior work
Any given section can contain UML or SQL schema diagrams, prose, or any other
conceivable free-form diagraming of my thoughts.
Observations & Triggers
The observation section is an attempt to keep a running log of the development
process as it takes place. In particular, this section:
- Records each step completed in the design plan
- Records each deviation from the original design plan and why
- Additional discoveries (references, unexpected findings in the code, external
change requests, refinement of the concepts and domain language)
- Each test run (both automated and manual), the outcome (both failure and
success), and any changes necessitated by observing the software in action
Once completed, the observation section is often the longest and most useful
component of an entry as it comes to contain both a record of all tests
completed (and implicitly all test branch we failed to examine) and a record of
all design decisions along with the catalyst for making each of those decisions.
I find the observation section is best managed using bullet journal
syntax as I record both notes on discoveries or tests and tasks as they are done
or occur to me in a free form mixed list. Skimming back each morning over the
list gives an excellent view of my thoughts for where I left off the day prior.
However, this only works if I remain disciplined. Thus, it is best to keep a
mental list of “triggers” to activate pausing and updating the observations
section. Mine include:
- Every time a design decision is made or rejected
- Every time we must reference an external source or look up a section of code
- Every time a test runs
Benefits
Largely, I have found that keeping a lab notebook, if done with discipline, has
been a wonderfully beneficial experiance as it:
- Cuts down on procrastination and time to mentally queue a design after a pause
from a given task since where I left off is plainly recorded
- Provides a written record of work for clients, employers, and stand-ups
- Provides a written record should a coworker join or take over a task, not to
mention your future self
- Reduces the possibility of “retreading” rejected designs or completed test
cases
- Encourages continuous refinement and improvement of the design plan through
the course of implementation
Cover photo: Trost, Fabian. “Leuchtturm” (CC BY-ND 2.0)
